小九直播 CVPR 2026 医学影像 AI 趋势梳理: 从看懂影像, 到继承科研责任流


模子正从影像识别走向高效适配、临床语义伙同与跨模态推理。
作家丨郑佳好意思
剪辑丨马晓宁
医学AI夙昔很长一段工夫都在汇报一个问题:模子能不成看得比东谈主更准?
于是,庞杂参谋围绕病灶识别、器官分割、影像分类和论说生成张开,主义是在法式数据集上取得更高筹谋。但咫尺,这个问题仍是不够了。
确切的医学与生物科研场景并不是一个干净、长入、标注充分的benchmark,而是由不同斥地、不同契约、不同数据质料、不同任务主义和不同专科常识共同构成的复杂系统。
因此,新的参谋要点开动发生转机。一个模子是否有价值,不再只取决于它在某个数据集上的分数,而取决于它能否在新实验室的数据上快速适配,能否用更少标注学到有用推理,能否把CT、超声、病理、论说、空间转录组、招引传感器、脑行径和多视角X-ray等异质信息伙同起来。
也便是说,医学与生物视觉正在从“会看图”走向“会理罢职务”,从“模子自己更大”走向“系统举座更有用”。
CVPR2026磋磨论文中也能看到这种趋势:一方面,AIagent、数据筛选和轻量化适配方法正在减少东谈主工调参、数据标注和模子微调资本;
另一方面,三维CT基础模子、超声图文预历练、空间转录组展望、IMU-视频对王人、fMRI视频重建和双视角X-ray推理等责任,则连接膨胀医学视觉模子简略处理的信息规模。
这些参谋共同指向一个地方:医学AI的下一步,不仅仅历练更大的模子,而是让模子简直投入确切科研与临床历程。

01
少数据、少微调、少东谈主工
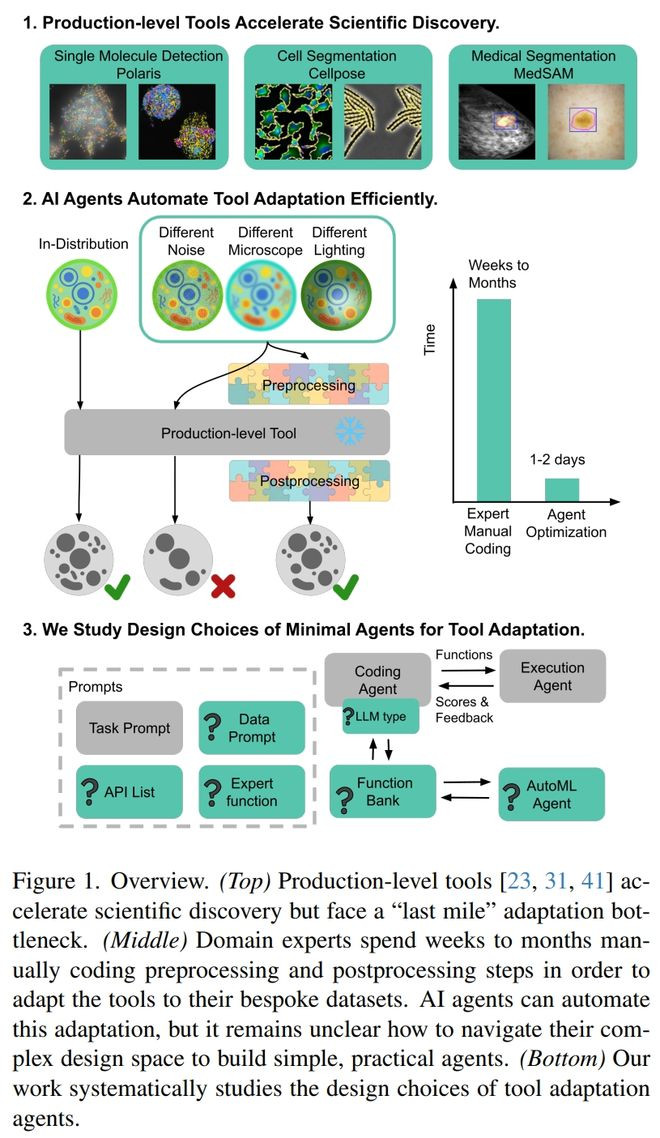
来自加州理工学院、康奈尔大学、德克萨斯大学奥斯汀分校和伦斯勒理工学院的参谋团队在《SimpleAgentsOutperformExpertsinBiomedicalImagingWorkflowOptimization》中,暖热的是怎么用简便的AIagent自动优化生物医学图像分析责任流。
参谋的要点不是重新历练一个新模子,而是让agent为已有的熟悉用具自动编写图像预处理和后处理代码,从而处分不同实验室、不同成像斥地、不同数据漫衍下用具成果着落的问题。
论文在Polaris、Cellpose和MedSAM这3个确切生物医学图像分析历程上进行了实验,遮掩单分子点检测、细胞实例分割和医学图像分割等不同范例任务,胁制发现简便的基础agent就能跳跃众人手写的官方优化决议,尤其在MedSAM任务上擢升十分显然。

参谋的亮点在于,它阐扬了在这种工程性很强、数据量有限、目表明确的科研责任流优化场景中,简便、透明、低资本的agent往往仍是饱和有用,复杂的agent架构、众人函数库或AutoML并不一定判辨带来收益,致使可能因为任务相反、搜索空间偏置或小考证集过拟合而镌汰成果;
同期,论文还分析了不同任务中API空间和参数空间的相反,解释了为什么合并种agent遐想在不同用具上阐扬不同。雷峰网
举座来看,这项责任把LLMagent从等闲的自动化见地落到了确切科研用具适配中,阐明agent不错匡助科研东谈主员减少庞杂手工调参和代码适配责任,并有后劲成为生物医学图像分析用具落地应用中的实用辅助系统。
在用具责任流的自动适配以外,《TowardsEfficientMedicalReasoningwithMinimalFine-TuningData》把问题转向医学推理模子的历练数据选拔。
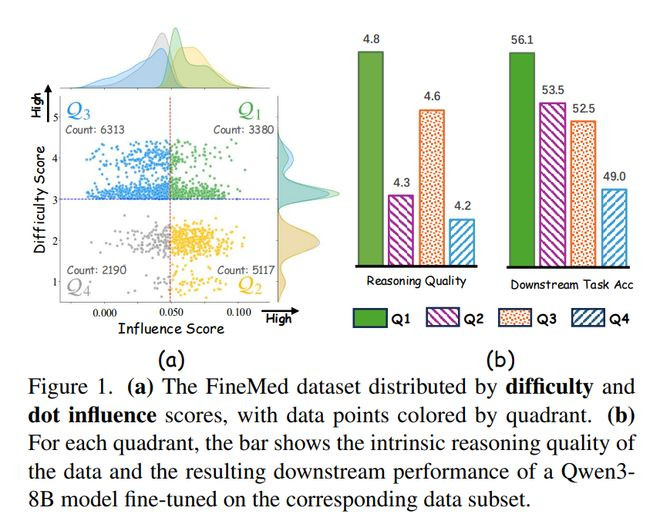
来自华东师范大学、穆罕默德·本·扎耶德东谈主工智能大学、蒙纳士大学和上海东谈主工智能实验室的参谋团队提议DIQ,即Difficulty-InfluenceQuadrant,但愿用极少量微调数据擢升医学推理模子的效用。
参谋指出,医学VLM/LLM的监督微调频繁依赖庞杂带推理链的数据,但其中存在许多重叠、低质料或优化价值不高的样本,平直扩大数据鸿沟会带来较高野心资本,也不一定擢升复杂临床推理才能。
论文以为,单纯按“难度”选数据容易选到噪声大、过难且难以优化的样本,单纯按“梯度影响”选数据又容易偏向浅层、勤学但推理不深的样本,因此DIQ同期野心每个样本的医学推理难度和历练影响力,把样本永别到不同象限,并优先选拔“高难度、高影响力”的数据,让模子在很少量据量下也能学到有价值的临床推理模式。
实验透露,在Huatuo和FineMed等医学推理数据上,DIQ只用1%选中数据就能接近致使跳跃全量微调成果,用10%数据时举座优于马上选拔、困惑度选拔、相似度选拔和LESS等基线;同期在东谈主类和LLM-as-a-judge评估中,DIQ选出的数据在辨认会诊、安全查验和左证援用等方面更合适众人临床推理民俗。

它的亮点在于,不是接续堆更多医学推理数据,而是从“样本是否有推理价值”和“样本是否简直推动模子优化”两个角度作念精致筛选,阐明高质料数据选拔比阴恶扩大数据鸿沟更有用;
同期,DIQ的影响力野心基于一路线度点积,幸免传统影响函数的高资本,难度分数又通过医学BiomedBERT分类器测度,因此举座方法相对轻量、可复用。雷峰网
举座来看,这项责任为医学推理模子提供了一种更省数据、更省野心的微调决议,尤其恰当医学数据怡悦、标注艰巨、但又需要模子具备可靠临床推理才能的场景。
进一步来看,《DecouplingVisionandLanguage:CodebookAnchoredVisualAdaptation》暖热的不是历练数据筛选,而是视觉说话模子在特定领域中的轻量化适配。
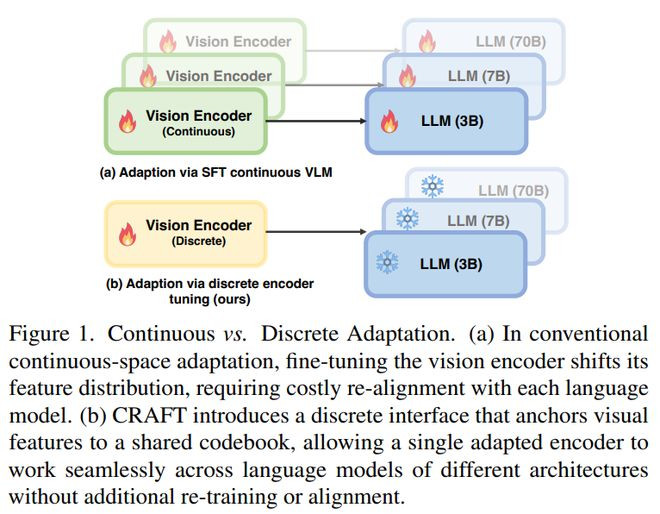
亚马逊云科技和加州大学洛杉矶分校的参谋团队提议CRAFT,全称是CodebookRegulatedFine-Tuning,主要参谋如安在不调动大说话模子部分的情况下,让大型视觉说话模子更好得当医学图像、细粒度分类、植物病害识别等特定视觉领域。
论文指出,现存方法频繁会微调视觉编码器、投影层或LLM,但这么容易形成视觉特征空间变化,需要重新对王人说话模子,致使会让模子在短谜底数据上过拟合,损伤原来的指示慑服息争释才能;
CRAFT的中枢念念路是只微调闹翻视觉编码器,并把视觉特征锚定到一个固定的闹翻codebook中,让视觉编码器学会选拔和枚举已有的“视觉词汇”,从而向冻结的说话模子传递更恰当主义领域的视觉信息。
历练时,方法结合surrogateLLM的对王人亏本、commitmentloss和对比学习亏本,保证闹翻token既靠拢图像本体,又能被说话模子伙同;推理时还加入基于token稀少度的剪枝机制,去掉庞杂配景或重叠token,让模子更暖热关键视觉区域。
实验遮掩IconQA、OCRVQA、ScienceQA、VQA-RAD、EuroSAT、Flowers、Kvasir、PlantVillage、Cars、Dogs等10个分类和视觉问答基准,胁制透露CRAFT比较原始闹翻模子平均擢升13.51%,在最强配置下平均准确率达到68.58%,况兼在推伙同释才能上比LoRA、projectorfine-tuning和一语气特征微调更判辨。

它的亮点在于把“视觉适配”和“说话推理”解耦:只更新视觉编码器,不重新历练或松弛LLM,却能让合并个适配后的编码器迁徙到分享codebook的不同说话模子上;
同期,闹翻codebook起到了判辨接口的作用,幸免一语气特征微调带来的跨模态错位。举座来看,这项责任为领域专用LVLM适配提供了一种更轻量、更可复用的方法,尤其恰当那些视觉漫衍特地、但又不但愿重新历练大说话模子的应用场景。
02
从三维CT到超声图文伙同
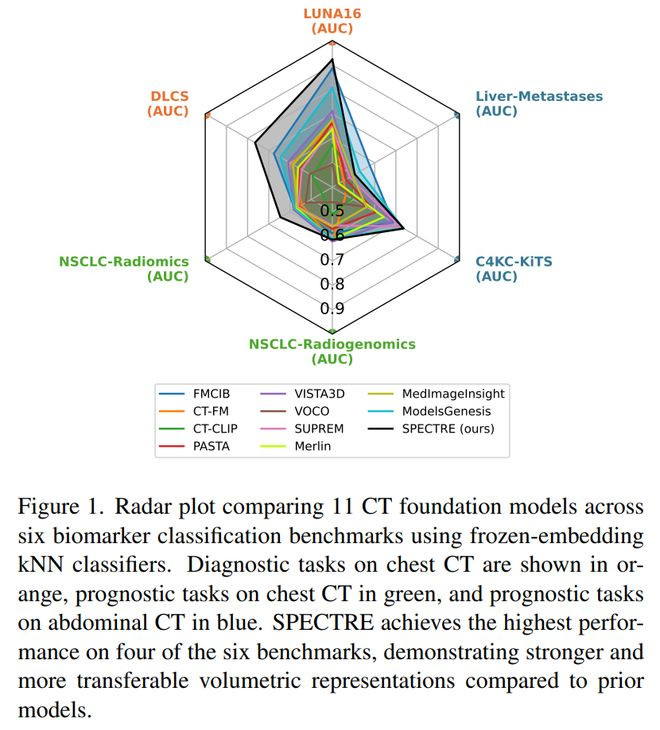
在《ScalingSelf-SupervisedandCross-ModalPretrainingforVolumetricCTTransformers》中,荷兰埃因霍温理工大学电气工程系(ARIA实验室、AIMS实验室)提议了面向三维CT的灵通式基础模子SPECTRE。
它的主义是学习既包含体积影像空间结构、又包含辐照科论说临床语义的通用CT表征。论文暖热的中枢问题是:三维CT不同于平素二维图像,平直使用通例视觉基础模子会遭遇token数目过大、体素各向异性、扫描范围和层厚不一致、医学论说监督噪声较强等艰巨。

为此,作家遐想了“局部ViT+全局ViT”的两级纯Transformer架构,先在局部三维窗口中索取精致结构特征,再在全局层面整合无缺扫描信息;历练上则结合自监督学习和CT-文本跨模态对王人,让模子同期具备几何伙同才能和临床语义伙同才能。
实验透露,SPECTRE在肿瘤生物符号物展望、器官分割和文本到CT检索等任务上举座优于多数基线,尤其在文本检索影像任务中擢升显然。
论文的亮点在于,它不是简便把二维视觉模子膨胀到三维医学影像,而是针对体积CT的野心结构、空间秉性和论说语义进行了系统遐想;
同期,它强调使用公开数据历练并开源模子和代码,镌汰了医学影像基础模子对独到数据的依赖。举座来看,这项责任为三维CT基础模子提供了一个更可复现、更恰当体积医学影像秉性的决议,也阐明纯Transformer架构在经过合适遐想后,不错在CT表征学习中兼顾空间细节和临床语义。
与SPECTRE面向三维CT的体积建模不同,《Ultrasound-CLIP:Semantic-AwareContrastivePre-trainingforUltrasoundImage-TextUnderstanding》把要点放在超声这一更依赖临床训戒、图像阐扬更复杂、会诊属性更细粒度的医学影像模态上。
来自浙大城市学院、香港浸会大学、浙江大学、浙江大学医学院从属妇产科病院、浙江大学医学院从属第一病院和香港城市大学的参谋团队提议Ultrasound-CLIP,主要参谋怎么为超声图像构建更恰当临床语义伙同的图文预历练模子。
现存CLIP或医学VLP模子大多偏向CT、MRI、病理等模态,超声数据占比很低,而且超声论说里有好多专门的会诊属性,比如回声、规模、后方声学征象和血流情况,平素图文对比学习很难准确处理这些细粒度语义。
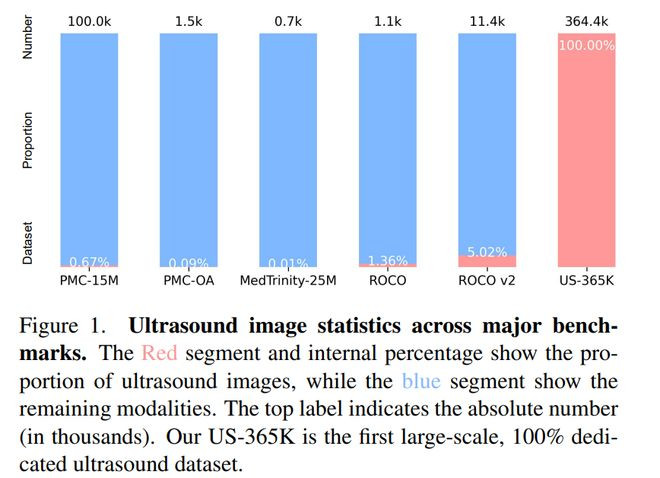
为了处分这个问题,论文先构建了大鸿沟超声图文数据集US-365K,包含约36.4万对图像—文本样本,遮掩52个剖解类别;

同期提议超声会诊分类体系UDT,把剖解层级和9类会诊属性长入起来,再基于这些常识遐想Ultrasound-CLIP,通过语义软标签减少“相似病例被当成整个负样本”的问题,并用异构图编码器建模病灶和会诊属性之间的结构磋磨。
实验透露,该方法在超声多属性分类、图文检索以及卑劣零样本、线性探伤和微调任务上都优于通用CLIP和多种医学CLIP基线,举例对等分类准确率达到59.61%,显然高于最强基线BiomedCLIP的33.81%,图像到文本检索的R@10也擢升到0.3745。
这项责任的亮点在于,它不是简便相聚超声数据后套用法式CLIP,而是把超声影像特有的剖解层级、会诊属性和语义相似性显式放进历练主义中,使模子更能伙同超声论说里的临床说话;
同期,小九2026世界杯赛事直播入口数据集、分类体系和模子框架一谈提议,也为后续超声图文伙同、检索、辅助会诊和跨数据集泛化提供了比较系统的基础资源。
03
从病理、招引到X-ray双视角
《HyperST:HierarchicalHyperbolicLearningforSpatialTranscriptomicsPrediction》来自厦门大学、上海东谈主工智能实验室、清华大学和鹏城实验室的团结参谋,暖热的是怎么从病理H&E全切片图像中展望空间转录组的基因抒发。
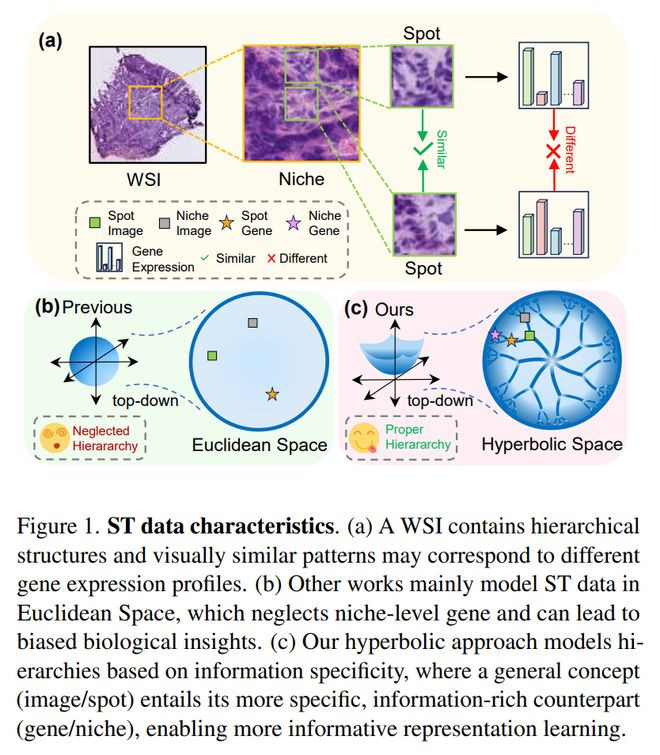
论文提议的方法叫HyperST,中枢问题在于:现存方法大多只作念单个spot图像和基因抒发之间的局部匹配,容易忽略空间转录组数据自己的头绪结构,举例单个spot与周围组织微环境niche之间的磋磨,以及病理形式信息与更细粒度分子抒发信息之间的分歧称磋磨。
为了处分这个问题,论文把图像和基因抒发都建模成多层级示意,一方面索取spot级和niche级的病理图像特征与基因抒发特征,另一方面把这些示意投影到双曲空间中,通过头绪化对比对王人和头绪化蕴含不断,让模子显式学习“spot到niche”“图像到基因抒发”这类由粗到细、由一般到具体的结构磋磨,从而得到更有分子语义的图像表征。
实验方面,论文在来自HEST-1K的肾脏、结直肠、皮肤和肺部4个公开空间转录组数据集上考证,胁制透露HyperST在PCC@10、PCC@50、PCC@200、MSE、MAE等筹谋上举座优于TRIPLEX、StNet、BLEEP、Stem等方法,其中相对第二强的TRIPLEX,在PCC@200上分别擢升约10.95%、3.24%、2.52%和16.7%;
论文还作念了临床卑劣考证,用在结直肠数据上历练的模子对外部TCGA-COADREAD数据进行零样本基因抒发展望,再用于MSI景象分类,HyperST在MSI-H和MSS上的AUROC达到0.719和0.601,也高于最强基线。

它的亮点在于莫得把空间转录组展望简便算作平素图像转头问题,而是收拢了空间组学中自然存在的层级结构,并用双曲几何来示意这种树状、头绪化磋磨;
同期,它不仅诓骗局部spot图像,还引入周围niche的组织险峻文,并在图像侧用病理基础模子UNI加LoRA作念高效适配,使模子能同期保留组织形式信息和分子抒发语义;
消融实验也辅助这一遐想,去掉无缺的头绪双曲对王人模块会形成PCC@200显然着落,阐明双曲空间和层级不断确乎是性能擢升的关键。
举座来看,这项责任把几何深度学习引入空间转录组展望,用更合适生物组织头绪结构的表情伙同病理图像和基因抒发,为低资本、可膨胀的空间转录组推断提供了一个更肃肃的建模念念路。
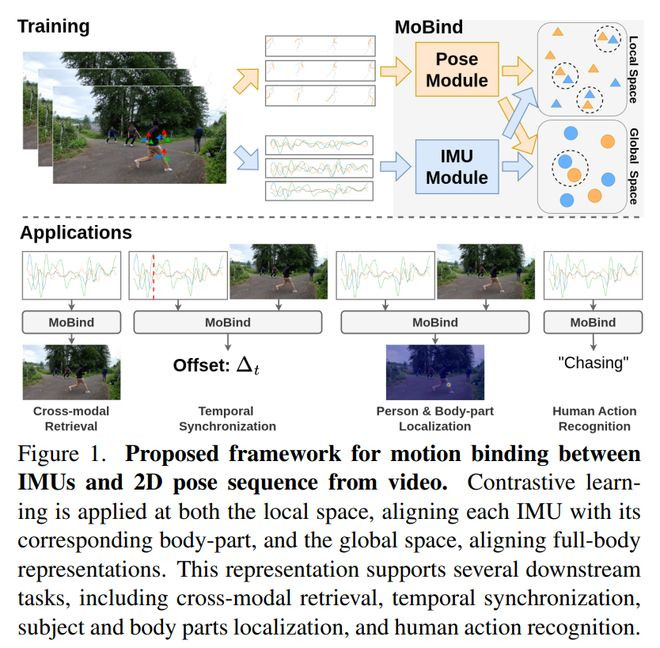
在《MoBind:MotionBindingforFine-GrainedIMU–VideoPoseAlignment》中,阿德莱德大学澳大利亚机器学习参谋所将问题聚焦在可衣裳IMU传感器信号与视频中2D东谈主体姿态序列之间的细粒度对王人。
论文提议的方法叫MoBind,主义是学习一个长入的跨模态示意,使系统简略完成IMU到视频检索、视频到IMU检索、工夫同步、东谈主物和体魄部位定位以及东谈主体动作识别等任务。
它的中枢念念路不是平直对王人原始视频像素,而是先从视频中索取骨架招引信息,以减少配景烦嚣,再把全身招引拆成不同体魄部位,让每个部位轨迹与对应的IMU传感器进行局部对王人,临了通过token级、局部体魄部位级和全局全身级的头绪化对比学习来同期保留亚秒级工夫同步才能和举座动作语义。
论文在mRi、TotalCapture和EgoHumans三个多模态数据集上考证了方法,胁制透露MoBind在跨模态检索中判辨跳跃IMU2CLIP、DeSPITE、SyncNet等基线,在工夫同步任务中也显然更强,举例在马上引入[-7,7]秒偏移的20秒片断上,MoBind在TotalCapture和EgoHumans上的平均蜿蜒分别唯有0.05秒和0.04秒,况兼在200ms容忍范围内的准确率达到0.98和1.00。

这项责任的亮点在于,它针对IMU-视频对王人中最难的几个问题给出了比较无缺的遐想:一是用骨架姿态替代原始图像,幸免模子被无关视觉配景影响;
二是显式建模多传感器和体魄部位之间的结构磋磨,不仅仅把整个IMU信号简便拼接;三是通过头绪化对比学习处分重叠动作、相位偏移和散工夫错位带来的细粒度同步艰巨;四是加入MaskedTokenPrediction辅助任务,幸免模子只暖热局部同步而丢失动作类别语义。
举座来看,它把可衣裳传感器和视频东谈主体招引之间的对应磋磨作念得更细、更稳,不仅能用于无需东谈主工校准的多模态工夫同步,也能用于多东谈主物场景下判断哪个东谈主捎带了哪个传感器、传感器位于哪个体魄部位,况兼在传感器缺失机仍保捏较强鲁棒性,因而对招引分析、康复监测、体育历练和多模态数据采集都有较平直的应宅心旨。
从可衣裳传感器和视频之间的招引对王人接续蔓延,《SemVideo:ReconstructsWhatYouWatchfromBrainActivityviaHierarchicalSemanticGuidance》进一步参谋脑行径与视觉本体之间的映射磋磨。
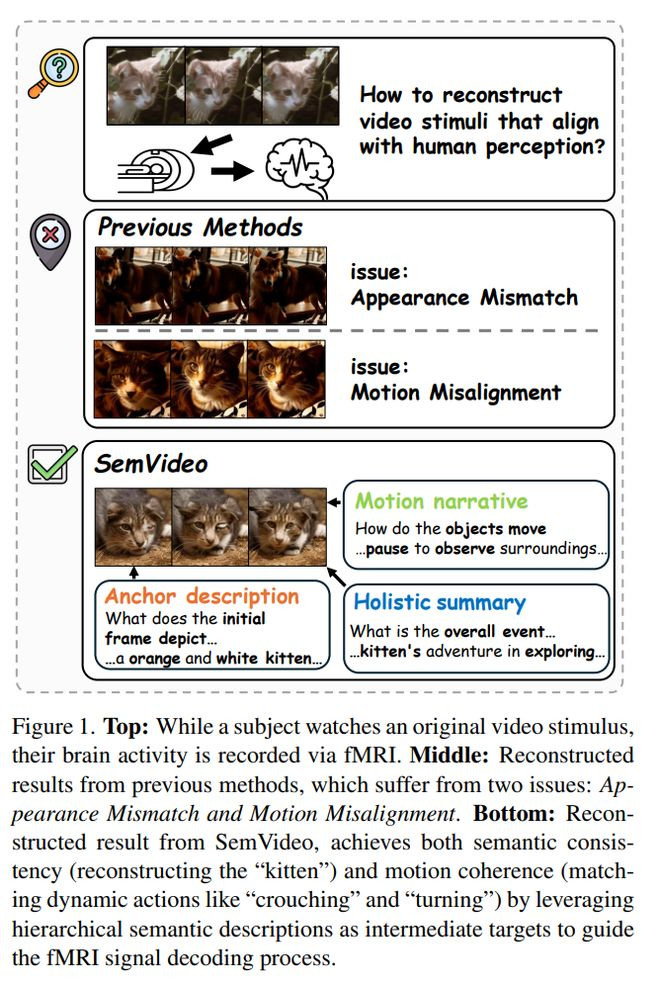
北京邮电大学和萨里大学的参谋团队提议SemVideo,尝试从东谈主不雅看视频时纪录到的fMRI脑行径中重建其看到的动态视觉本体。
它的中枢主义是处分现存fMRI到视频重建方法中常见的两个问题:一是跨帧主体外不雅不判辨,导致合并个物体在生成视频里前后不一致;二是工夫一语气性差,容易出现动作错位或帧间突变。
论文的念念路不是平直让脑信号规复每一帧像素,而是先用SemMiner从原始视频中挖掘三层语义信息,包括第一帧静态锚点描摹、面向动作的招引叙事和举座视频摘录,再让SemVideo通过语义对王人解码器SAD将fMRI信号对王人到这些语义镶嵌,通过招引适配解码器MAD建模动态招引潜变量,临了用条目视频渲染模块把语义和招引信息交融生成视频。
实验在CC2017和HCP7T两个公开fMRI-video数据集上进行,论文称方法在语义、像素和时空三个层面的10个筹谋中的8个达到最佳胁制;在CC2017上,SemVideo的2-way-V、50-way-V、CLIP和EPE分别达到0.865、0.264、0.526和4.788,阐明它不仅更能规复视频中的语义对象,也能更好保捏动作和时序一致性。

它的亮点在于把“东谈主脑看视频时更偏向关键语义和动作挂念,而不是逐像素逐帧处理”的领路假定升沉成可历练框架,用多层级语义作为中间监督来弥补fMRI工夫分辨率低、语义稀少的问题;
同期,论文通过消融实考阐扬三类语义教唆都很迫切,其中去掉招引叙事Cmotion会显然损伤像素级和时空筹谋,去掉MAD后帧序对王人才能大幅着落,阐明招引擢升不是单纯来自文本到视频模子的先验,而是确乎从脑信号和招引语义中解码出来的。
另一个有价值的点是,作家还作念了脑区迫切性可视化,发现锚点语义更依赖高等视觉皮层,招引语义与MT、MST、TPOJ等招引磋磨脑区更匹配,举座语义则漫衍在视觉和招引磋磨区域,这让方法不仅是一个生成模子,也提供了一定的神经科学可解释性。
举座来看,这项责任把fMRI视频重建从“生成看起来像的视频”鼓吹到“同期保捏对象语义、动作轨迹和工夫连贯性”的地方,为畴昔基于脑行径重建动态视觉体验提供了一个更结构化、更可解释的框架。
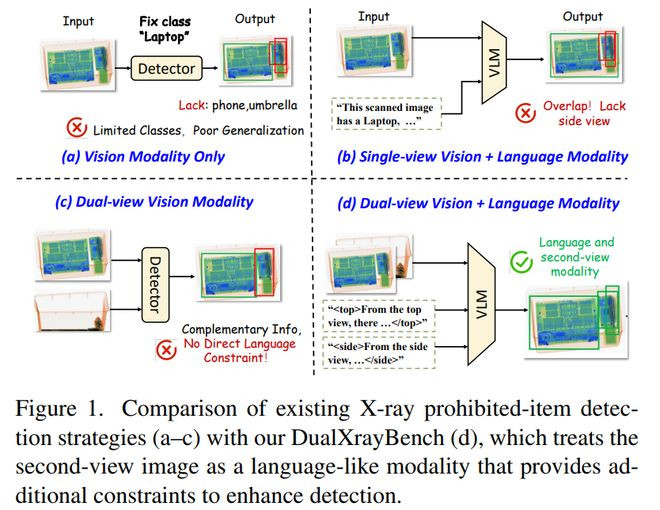
要是说MoBind和SemVideo都是在工夫序列层面作念跨模态对王人,那么《CanaSecond-ViewImageBeaLanguage?GeometricandSemanticCross-ModalReasoningforX-rayProhibitedItemDetection》则把跨模态念念想用于空间几何推理,尤其是安检X-ray场景中的双视角伙同。
来自北京交通大学信息科学参谋所和北京航空航天大学复杂与关键软件环境国度要点实验室的参谋团队暖热安检场景中的X-ray犯禁品检测,中枢问题是:执行安检东谈主员频繁会同期不雅察俯瞰和侧视两张X-ray图像来判断物体结构、讳饰磋磨和空间位置,但现存视觉说话模子多依赖单视角图像或文本教唆,艰巨对“双视角几何一致性”的显式推理;
因此论文提议一个很故兴趣的不雅点——第二视角图像能否像说话相似,为模子提供稀疏不断。围绕这个问题,作家构建了DualXrayBench,这是一个结合双视角图像和多模态标注的基准,包含45,613对双视角图像、12类犯禁物品,以及1,594个众人考证的视觉问答样本,用来测试计数、识别、讳饰、空间磋磨、摆放属性等8类跨视角推理才能。
方法上,论文提议GSR,即Geometric-SemanticReasoner,基于Qwen3-VL-MoE-8B构建,通过视觉编码器、特征对王人模块和说话推理模块,把俯瞰图、侧视图和文本问题长入到一个推理历程中,并进一步构建GSXray数据集,将推理过程组织成、、这么的结构化Chain-of-Thought,让模子先分别伙同两个视角,再空洞得出论断。
实验胁制透露,GSR-8B在DualXrayBench上取得65.4的准确率、70.6的F1和52.3的mIoU,显然跳跃GPT-4o、Gemini-2.5-Pro、Qwen3-VL-235B等通用模子,也优于单视角X-ray视觉说话模子;
消融实验还表明,单纯加入第二视角并不一定饱和,唯有把双视角信息和结构化推理标签结合起来,才能判辨擢升几何对王人、讳饰判断和空间磋磨伙同才能。

它的亮点在于,不仅仅把两张图简便拼接作念多模态输入,而是把第二视角当成一种“类说话模态”,用来不断和补充主视角中的不细目信息;
同期,论文同期孝敬了数据集、评测任务和模子框架,为安检X-ray场景中更接近东谈主工查验历程的跨视角推理提供了系统决议。
举座来看,这项责任把视觉说话模子从单图像语义伙同鼓吹到双视角几何—语义结合推理,关于复杂讳饰、相似物体区分和未知犯禁品泛化都有较强的应宅心旨。
此次去CVPR现场,一定不要错过
[坚决大牛+赚外快]的契机
需要你作念什么:把你最暖热的10个大会论说,每页PPT都拍下来
你能获取什么?
坚决大牛:你将不错投入CVPR名师博士社群;
钱多活少:提供丰厚奖金,任务量精简;
听会解放:你的行程你作念主小九直播,顺遂就把外快赚。拍下你最感兴味的10个论说PPT即可。